产品设计
星辰处理器
药物化学
redis
电商
散列表
知识蒸馏
jmeter
安全威胁分析
websocket
ras
进程替换
元开发
正则
2022
pyqt
salesforce
word
移动魔百盒
string
爬虫代理
2024/4/11 19:19:43
跨越网络边界:借助C++编写的下载器程序,轻松获取Amazon商品信息
背景介绍
在数字化时代,数据是新的石油。企业和开发者都在寻找高效的方法来收集和分析网络上的信息。亚马逊,作为全球最大的电子商务平台之一,拥有丰富的商品信息,这对于市场分析和竞争情报来说是一个宝贵的资源。
问题陈述
然…

如何解决爬虫程序访问速度受限问题
目录
前言
一、代理IP的获取
1. 自建代理IP池
2. 购买付费代理IP
3. 使用免费代理IP网站
二、代理IP的验证
三、使用代理IP进行爬取
四、常见问题和解决方法
1. 代理IP不可用
2. 代理IP速度慢
3. 代理IP被封禁
总结 前言
解决爬虫程序访问速度受限问题的一种常用方…

如何配置Apache的反向代理
目录
前言
一、反向代理的工作原理
二、Apache反向代理的配置
1. 安装Apache和相关模块
2. 配置反向代理规则
3. 重启Apache服务器
三、常见的使用案例
1. 负载均衡
2. 缓存
3. SSL加密
总结 前言
随着Web应用程序的不断发展和扩展,需要处理大量的请求和…

使用 Python Selenium 提取动态生成下拉选项
在进行网络数据采集和数据分析时,处理动态生成的下拉菜单是一个常见的挑战。Selenium是一个强大的Python库,可以让你自动化浏览器操作,比如从动态生成的下拉菜单中选择选项。这是一个常见的网页爬虫和数据收集者面临的挑战,但是Se…

使用Puppeteer爬取地图上的用户评价和评论
导语
在互联网时代,获取用户的反馈和意见是非常重要的,它可以帮助我们了解用户的需求和喜好,提高我们的产品和服务质量。有时候,我们需要从地图上爬取用户对某些地点或商家的评价和评论,这样我们就可以分析用户对不同…

使用C#和HtmlAgilityPack打造强大的Snapchat视频爬虫
概述
Snapchat作为一款备受欢迎的社交媒体应用,允许用户分享照片和视频。然而,由于其特有的内容自动消失特性,爬虫开发面临一些挑战。本文将详细介绍如何巧妙运用C#和HtmlAgilityPack库,构建一个高效的Snapchat视频爬虫。该爬虫能…

一小时掌握:使用ScrapySharp和C#打造新闻下载器
引言
爬虫技术是指通过编程的方式,自动从互联网上获取和处理数据的技术。爬虫技术有很多应用场景,比如搜索引擎、数据分析、舆情监测、电商比价等。爬虫技术也是一门有趣的技术,可以让你发现网络上的各种有价值的信息。
本文将介绍如何使用…

git怎么设置http代理服务器
目录
前言
一、什么是HTTP代理服务器
二、为什么需要设置HTTP代理服务器
三、如何设置HTTP代理服务器
1. 查看当前是否已经存在全局代理设置
2. 设置全局代理
3. 验证代理设置
4. 取消代理设置
四、示例代码
五、总结 前言
Git是一个非常强大的版本控制工具…

使用Objective-C和ASIHTTPRequest库进行Douban电影分析
概述
Douban是一个提供图书、音乐、电影等文化内容的社交网站,它的电影频道包含了大量的电影信息和用户评价。本文将介绍如何使用Objective-C语言和ASIHTTPRequest库进行Douban电影分析,包括如何获取电影数据、如何解析JSON格式的数据、如何使用代理IP技…

增强Java技能:使用OkHttp下载www.dianping.com信息
在这篇技术文章中,我们将探讨如何使用Java和OkHttp库来下载并解析www.dianping.com上的商家信息。我们的目标是获取商家名称、价格、评分和评论,并将这些数据存储到CSV文件中。此外,我们将使用爬虫代理来绕过任何潜在的IP限制,并实…

C#和HttpClient结合示例:微博热点数据分析
概述
微博是中国最大的社交媒体平台之一,它每天都会发布各种各样的热点话题,反映了网民的关注点和舆论趋势。本文将介绍如何使用C#语言和HttpClient类来实现一个简单的爬虫程序,从微博网站上抓取热点话题的数据,并进行一些基本的…

如何选择合适的IP代理,如何为网络爬虫设置代理
目录
前言
1. 代理类型的选择
2. 代理速度
3. 代理稳定性
4. 代理的匿名性
5. 代理的地理位置
总结 前言
在进行网络爬虫任务时,为了避免被目标网站封禁IP或限制访问频率,我们通常会使用代理来隐藏真实的IP地址。选择合适的IP代理对于爬虫的成功…

解析Perl爬虫代码:使用WWW__Mechanize__PhantomJS库爬取stackoverflow.com的详细步骤
在这篇文章中,我们将探讨如何使用Perl语言和WWW::Mechanize::PhantomJS库来爬取网站数据。我们的目标是爬取stackoverflow.com的内容,同时使用爬虫代理来和多线程技术以提高爬取效率,并将数据存储到本地。
Perl爬虫代码解析
首先࿰…

使用PySpider进行IP代理爬虫的技巧与实践
目录
前言
一、安装与配置PySpider
二、使用IP代理
三、IP代理池的使用
四、处理代理IP的异常
五、总结 前言
IP代理爬虫是一种常见的网络爬虫技术,可以通过使用代理IP来隐藏自己的真实IP地址,防止被目标网站封禁或限制访问。PySpider是一个基于P…

安卓群控代理ip问题怎么解决
目录
写在前面
一、问题背景
二、解决方案
1. 获取代理IP池
2. 配置代理IP
3. 使用代理IP进行网络请求
4. 使用代理IP轮流访问
三、总结 写在前面
解决安卓群控代理IP问题的方法有很多种,下面给出一种通过代码实现的解决方案,该方案能够实现对安…

如何获取美团的热门商品和服务
导语
美团是中国最大的生活服务平台之一,提供了各种各样的商品和服务,如美食、酒店、旅游、电影、娱乐等。如果你想了解美团的热门商品和服务,你可以使用爬虫技术来获取它们。本文将介绍如何使用Python和BeautifulSoup库来编写一个简单的爬虫…

PHP爬虫技术:利用simple_html_dom库分析汽车之家电动车参数
摘要/导言
本文旨在介绍如何利用PHP中的simple_html_dom库结合爬虫代理IP技术来高效采集和分析汽车之家网站的电动车参数。通过实际示例和详细说明,读者将了解如何实现数据分析和爬虫技术的结合应用,从而更好地理解和应用相关技术。
背景/引言
随着电…

代理IP安全问题:在国外使用代理IP是否安全
目录
前言
一、国外使用代理IP的安全风险
1. 数据泄露
2. 恶意软件
3. 网络攻击
4. 法律风险
二、保护国外使用代理IP的安全方法
1. 选择可信的代理服务器
2. 使用加密协议
3. 定期更新系统和软件
4. 注意网络安全意识
三、案例分析
总结 前言
在互联网时代&…

Kotlin+Apache HttpClient+代理服务器=高效的eBay图片爬虫
引入
你是否想过用Kotlin来编写爬虫程序?你是否想过用Apache HttpClient来处理HTTP请求和响应?你是否想过用代理服务器来绕过反爬措施?如果你的答案是肯定的,那么本文将为你介绍一种高效的eBay图片爬虫的实现方式,让你…

C++下载器程序:如何使用cpprestsdk库下载www.ebay.com图片
本文介绍了如何使用C语言和cpprestsdk库编写一个下载器程序,该程序可以从www.ebay.com网站上下载图片,并保存到本地文件夹中。为了避免被网站屏蔽,我们使用了亿牛云爬虫代理服务提供的代理IP地址,以及多线程技术提高下载效率。
首…

利用RoboBrowser库和爬虫代理实现微博视频的爬取
技术概述
微博是一个社交媒体平台,用户可以在上面发布和分享各种内容,包括文字、图片、音频和视频。微博视频是微博上的一种重要的内容形式,有时我们可能想要下载微博视频到本地,以便于观看或分析。但是,微博视频并没…
Python和BeautifulSoup库的魔力:解析TikTok视频页面
概述
短视频平台如TikTok已成为信息传播和电商推广的重要渠道。用户通过短视频分享生活、创作内容,吸引了数以亿计的观众,为企业和创作者提供了广阔的市场和宣传机会。然而,要深入了解TikTok上的视频内容以及用户互动情况,需要借…

加速数据采集:用OkHttp和Kotlin构建Amazon图片爬虫
引言
曾想过轻松获取亚马逊上的商品图片用于项目或研究吗?是否曾面对网络速度慢或被网站反爬虫机制拦截而无法完成数据采集任务?如果是,那么本文将为您介绍如何用OkHttp和Kotlin构建一个高效的Amazon图片爬虫解决方案。
背景介绍
亚马逊&a…

使用Puppeteer构建博客内容的自动标签生成器
导语
标签是一种用于描述和分类博客内容的元数据,它可以帮助读者快速找到感兴趣的主题,也可以提高博客的搜索引擎优化(SEO)。然而,手动为每篇博客文章添加合适的标签是一件费时费力的工作,有时候也容易遗漏…

超越常规:用PHP抓取招聘信息
在人力资源管理方面,有效的数据采集可以为公司提供宝贵的人才洞察。通过分析招聘网站上的职位信息,人力资源专员可以了解市场上的人才供给情况,以及不同行业和职位的竞争状况。这样的数据分析有助于企业制定更加精准的招聘策略,从…

实用技巧:在C和cURL中设置代理服务器爬取www.ifeng.com视频
概述:
网络爬虫技术作为一种自动获取互联网数据的方法,在搜索引擎、数据分析、网站监测等领域发挥着重要作用。然而,面对反爬虫机制、网络阻塞、IP封禁等挑战,设置代理服务器成为解决方案之一。代理服务器能够隐藏爬虫的真实IP地…

Python如何爬取免费爬虫ip
做过大数据抓取的程序员应该都知道,正常市面上的爬虫ip只分为两种,一种是API提取式的,还有一种是账密形式隧道模式的。往往因为高昂费用而止步。对于初学者觉得没有必要,我们知道每个卖爬虫ip的网站有的提供了免费IP,可…
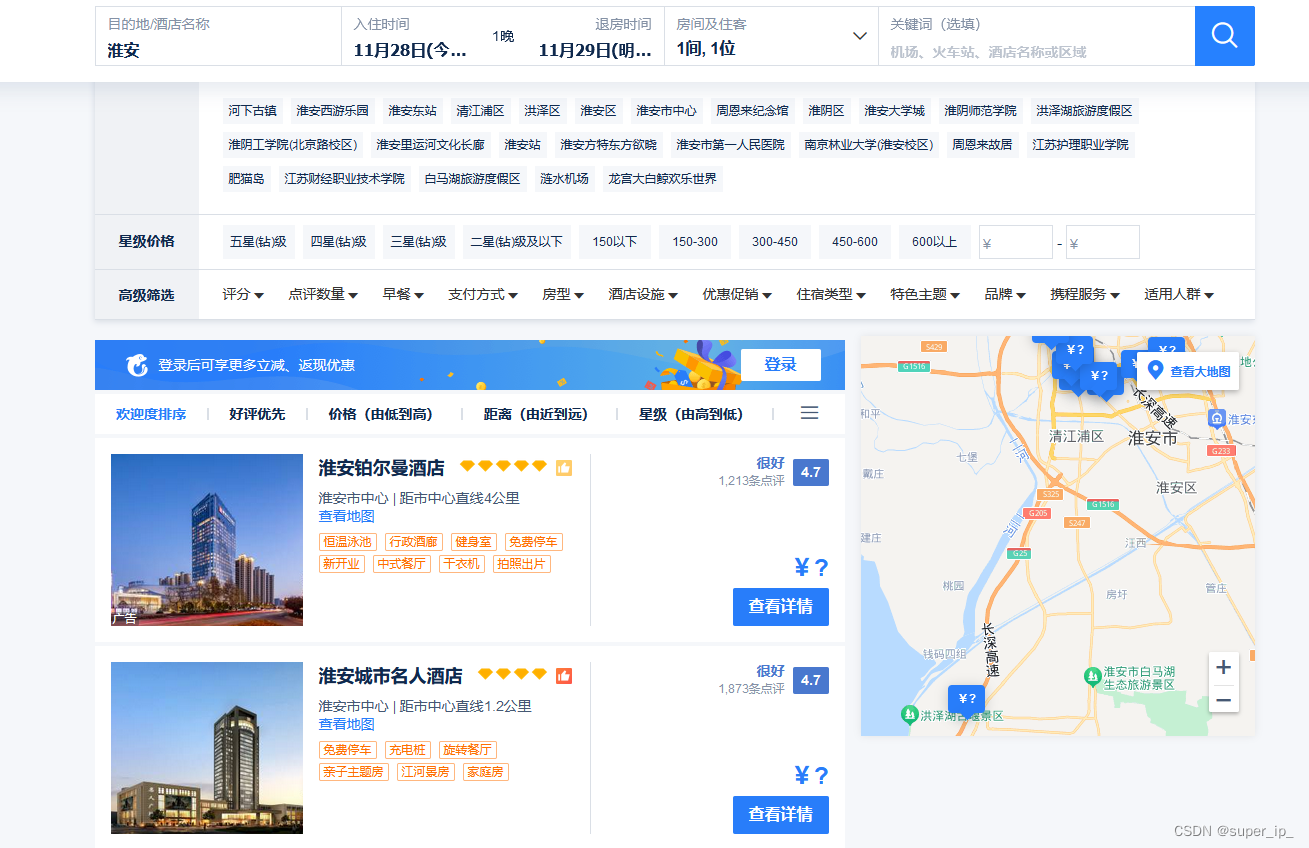
python如何抓取携程酒店的价格,让工作更简单点
有时候老板没事安排点事,为了偷懒,只能使出大招,毕竟自己不是那么老老实实干活的人,整理数据这类累和繁琐的活,我怎么能轻易动,好在gpt可以帮我来实现,有人可能会说,这么点内容你还不…

突破技术边界:R与jsonlite库探秘www.snapchat.com的数据之旅
概述
Snapchat是一款流行的社交媒体应用,它允许用户发送和接收带有滤镜和贴纸的照片和视频,以及创建和观看故事和发现内容。Snapchat的数据是非常有价值的,因为它可以反映用户的行为、偏好和趋势。然而,Snapchat的数据并不容易获…

如何在C程序中使用libcurl库下载网页内容
概述
爬虫是一种自动获取网页内容的程序,它可以用于数据采集、信息分析、网站监测等多种场景。在C语言中,有一个非常强大和灵活的库可以用于实现爬虫功能,那就是libcurl。libcurl是一个支持多种协议和平台的网络传输库,它提供了一…

爬虫技术对携程网旅游景点和酒店信息的数据挖掘和分析应用
导语
爬虫技术是一种通过网络爬取目标网站的数据并进行分析的技术,它可以用于各种领域,如电子商务、社交媒体、新闻、教育等。本文将介绍如何使用爬虫技术对携程网旅游景点和酒店信息进行数据挖掘和分析,以及如何利用Selenium库和代理IP技术…

Go编程:使用 Colly 库下载Reddit网站的图像
概述
Reddit是一个社交新闻网站,用户可以发布各种主题的内容,包括图片。本文将介绍如何使用Go语言和Colly库编写一个简单的爬虫程序,从Reddit网站上下载指定主题的图片,并保存到本地文件夹中。为了避免被目标网站反爬,…

简单而高效:使用PHP爬虫从网易音乐获取音频的方法
概述
网易音乐是一个流行的在线音乐平台,提供了海量的音乐资源和服务。如果你想从网易音乐下载音频文件,你可能会遇到一些困难,因为网易音乐对其音频资源进行了加密和防盗链的处理。本文将介绍一种使用PHP爬虫从网易音乐获取音频的方法&…

Swift使用Embassy库进行数据采集:热点新闻自动生成器
概述
爬虫程序是一种可以自动从网页上抓取数据的软件。爬虫程序可以用于各种目的,例如搜索引擎、数据分析、内容聚合等。本文将介绍如何使用Swift语言和Embassy库编写一个简单的爬虫程序,该程序可以从新闻网站上采集热点信息,并生成一个简单…

轻松解锁微博视频:基于Perl的下载解决方案
引言
随着微博成为中国最受欢迎的社交平台之一,其内容已经变得丰富多彩,特别是视频内容吸引了大量用户的关注。然而,尽管用户对微博上的视频内容感兴趣,但却面临着无法直接下载这些视频的难题。本文旨在介绍一个基于Perl的解决方…

使用代理IP技术实现爬虫同步获取和保存
概述
在网络爬虫中,使用代理IP技术可以有效地提高爬取数据的效率和稳定性。本文将介绍如何在爬虫中同步获取和保存数据,并结合代理IP技术,以提高爬取效率。
正文
代理IP技术是一种常用的网络爬虫技术,通过代理服务器转发请求&a…

踏入网页抓取的旅程:使用 grequests 构建 Go 视频下载器
引言
在当今数字化的世界中,网页抓取技术变得越来越重要。无论是获取数据、分析信息,还是构建自定义应用程序,我们都需要从互联网上抓取数据。本文将介绍如何使用 Go 编程语言和 grequests 库来构建一个简单的 Bilibili 视频下载器ÿ…

挑战音频爬虫的技术迷宫:Watir和Ruby的奇妙合作
概述
音频爬虫是一种可以从网站上抓取音频文件的程序。音频爬虫的应用场景很多,比如语音识别、音乐推荐、声纹分析等。然而,音频爬虫也面临着很多技术挑战,比如音频文件的格式、编码、加密、隐藏、动态加载等。如何突破这些技术障碍…

使用PHP实现动态代理IP的功能
目录
前言
一、 什么是代理IP
二、动态代理IP的原理
三、使用ProxyCrawl API获取代理IP
安装和配置
发送请求获取代理IP
实现动态代理IP的功能
总结 前言
动态代理IP是一种通过不断切换不同的代理IP来隐藏真实IP地址的技术。在使用网络爬虫、进行数据采集、访问被封IP…

挖掘网络宝藏:利用Scala和Fetch库下载Facebook网页内容
介绍
在数据驱动的世界里,网络爬虫技术是获取和分析网络信息的重要工具。本文将探讨如何使用Scala语言和Fetch库来下载Facebook网页内容。我们还将讨论如何通过代理IP技术绕过网络限制,以爬虫代理服务为例。
技术分析
Scala是一种多范式编程语言&…

爬蟲IP代理詳細指南
收集數據算是比較麻煩的任務,尤其是當數據量很大時。在網路抓取時暴露IP地址是常有的事,所以需要用到代理抓取工具,提供高效可靠的數據提取。
爬蟲IP代理抓取工具到底指什麼,以及如何在各種情況下使用它,比如說繞過地…

网络爬虫的实战项目:使用JavaScript和Axios爬取Reddit视频并进行数据分析
概述
网络爬虫是一种程序或脚本,用于自动从网页中提取数据。网络爬虫的应用场景非常广泛,例如搜索引擎、数据挖掘、舆情分析等。本文将介绍如何使用JavaScript和Axios这两个工具,实现一个网络爬虫的实战项目,即从Reddit这个社交媒…

利用爬虫技术自动化采集汽车之家的车型参数数据
导语
汽车之家是一个专业的汽车网站,提供了丰富的汽车信息,包括车型参数、图片、视频、评测、报价等。如果我们想要获取这些信息,我们可以通过浏览器手动访问网站,或者利用爬虫技术自动化采集数据。本文将介绍如何使用Python编写…

使用Puppeteer进行游戏数据可视化
导语
Puppeteer是一个基于Node.js的库,可以用来控制Chrome或Chromium浏览器,实现网页操作、截图、测试、爬虫等功能。本文将介绍如何使用Puppeteer进行游戏数据的爬取和可视化,以《英雄联盟》为例。
概述
《英雄联盟》是一款由Riot Games开…

Restclient-cpp库介绍和实际应用:爬取www.sohu.com
概述
Restclient-cpp是一个用C编写的简单而优雅的RESTful客户端库,它可以方便地发送HTTP请求和处理响应。它基于libcurl和jsoncpp,支持GET, POST, PUT, PATCH, DELETE, HEAD等方法,以及自定义HTTP头部,超时设置,代理服…

C#编程艺术:Fizzler库助您高效爬取www.twitter.com音频
数据是当今数字时代的核心资源,但是从互联网上抓取数据并不容易。本文将教您如何利用C#编程艺术和Fizzler库高效爬取Twitter上的音频数据,让您轻松获取所需信息。
Twitter简介
Twitter是全球最大的社交媒体平台之一,包含丰富的音频资源。用…

使用多线程或异步技术提高图片抓取效率
导语
图片抓取是爬虫技术中常见的需求,但是图片抓取的效率受到很多因素的影响,比如网速、网站反爬机制、图片数量和大小等。本文将介绍如何使用多线程或异步技术来提高图片抓取的效率,以及如何使用爬虫代理IP来避免被网站封禁。
概述
多线…

Haskell网络编程:从数据采集到图片分析
概述
爬虫技术在当今信息时代中发挥着关键作用,用于从互联网上获取数据并进行分析。本文将介绍如何使用Haskell进行网络编程,从数据采集到图片分析,为你提供一个清晰的指南。我们将探讨如何使用亿牛云爬虫代理来确保高效、可靠的数据获取&am…

如何使用Puppeteer进行新闻网站数据抓取和聚合
导语
Puppeteer是一个基于Node.js的库,它提供了一个高级的API来控制Chrome或Chromium浏览器。通过Puppeteer,我们可以实现各种自动化任务,如网页截图、PDF生成、表单填写、网络监控等。本文将介绍如何使用Puppeteer进行新闻网站数据抓取和聚…

打破常规思维:Scrapy处理豆瓣视频下载的方式
概述
Scrapy是一个强大的Python爬虫框架,它可以帮助我们快速地开发和部署各种类型的爬虫项目。Scrapy提供了许多方便的功能,例如请求调度、数据提取、数据存储、中间件、管道、信号等,让我们可以专注于业务逻辑,而不用担心底层的…

Amazon图片下载器:利用Scrapy库完成图像下载任务
概述
本文介绍了如何使用Python的Scrapy库编写一个简单的爬虫程序,实现从Amazon网站下载商品图片的功能。Scrapy是一个强大的爬虫框架,提供了许多方便的特性,如选择器、管道、中间件、代理等。本文将重点介绍如何使用Scrapy的图片管道和代理…

豆瓣图书评分数据的可视化分析
导语
豆瓣是一个提供图书、电影、音乐等文化产品的社区平台,用户可以在上面发表自己的评价和评论,形成一个丰富的文化数据库。本文将介绍如何使用爬虫技术获取豆瓣图书的评分数据,并进行可视化分析,探索不同类型、不同年代、不同…

从零开始制作一个Douban图像下载器:Wt库的基础知识和操作指南
引言
欢迎来到本文,如果你希望从豆瓣下载海量的高清图像、学习使用现代C web应用程序框架Wt库开发web应用程序,或者了解如何利用代理IP和多线程技术提高爬虫效率和稳定性,那么你来对地方了。在接下来的内容中,我们将为你提供一个…

使用GoQuery实现头条新闻采集
概述
在本文中,我们将介绍如何使用Go语言和GoQuery库实现一个简单的爬虫程序,用于抓取头条新闻的网页内容。我们还将使用爬虫代理服务,提高爬虫程序的性能和安全性。我们将使用多线程技术,提高采集效率。最后,我们将展…
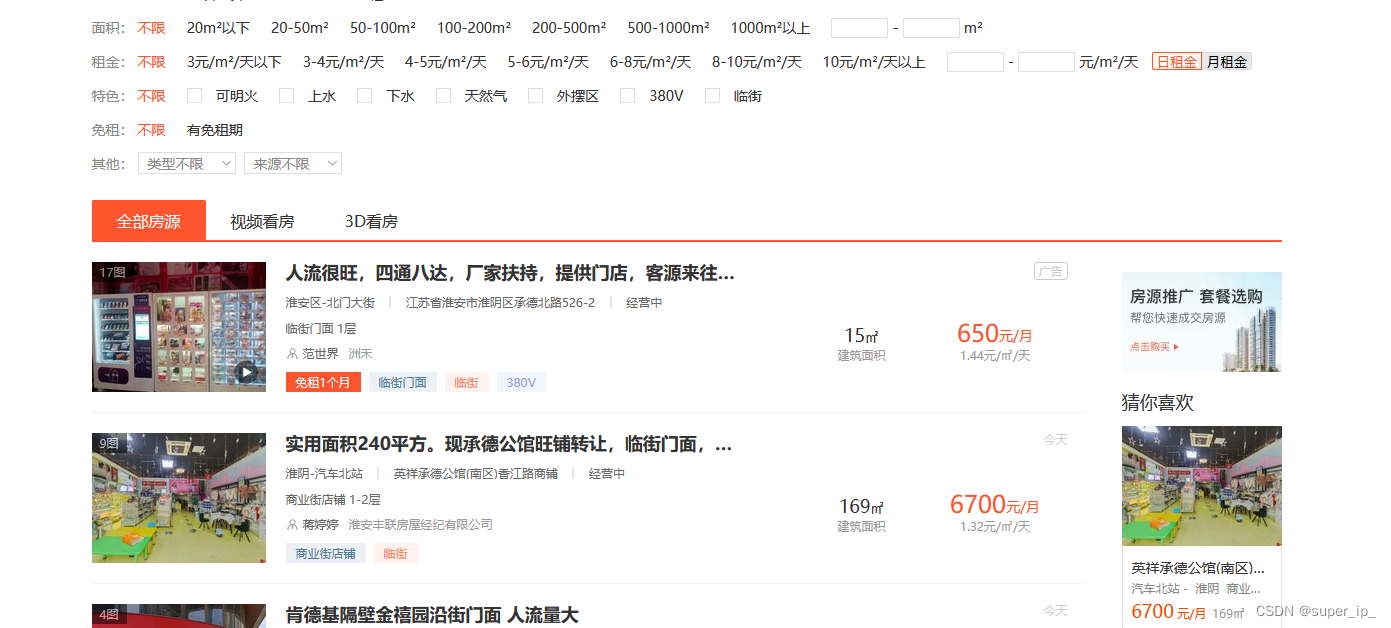
帮亲戚个忙,闲来有事用php写个58商铺出租转让信息抓取
最近亲戚想做点小超市生意,但是又不懂互联网,信息获取有点闭塞。知道我身在互联网大潮中,想让我帮忙看看网上有没有商铺转让的。心想,这不是小菜一碟,大显身手的时候来了,大概去58瞅了瞅,这玩意…

巧用简单工具:PHP使用simple_html_dom库助你轻松爬取JD.com
概述
爬虫技术是一种从网页上自动提取数据的方法,它可以用于各种目的,比如数据分析、网站监控、竞争情报等。爬虫技术的难度和复杂度取决于目标网站的结构和反爬策略,有些网站可能需要使用复杂的工具和技巧才能成功爬取,而有些网…

深入探讨网络抓取:如何使用 Scala 和 Dispatch 获取 LinkedIn 图片
网络抓取是一种从互联网上获取数据的技术,它可以用于各种目的,例如数据分析、信息检索、竞争情报等。网络抓取的过程通常包括以下几个步骤:
发送 HTTP 请求到目标网站解析响应的 HTML 文档提取所需的数据存储或处理数据
在本文中࿰…

提升数据采集技能:用 Axios 实现的 Twitter 视频下载器全面解析
引入
在当今数据驱动的时代,高效的数据采集是实现成功数据科学项目的关键。数据采集不仅涉及到数据的获取,还包括数据的清洗、转换、存储和分析等多个环节。Twitter作为全球最大的社交媒体平台之一,蕴含着丰富的信息和海量的多媒体内容&…